
JavaScript反爬虫原理
Created|Updated
|Post Views:
css和JS修改浏览器的DOM
在我们可以浏览到的网页中,他们设置的反爬虫机制就是通过css和js修改原本html文件中的标签内容(把数据内容放到js中),使得我们无法直接从html文件中获得我们想要的数据。也就是利用了我们平常的爬虫工具中没有js解释器和css解释器这一个弊端达到了反爬的效果
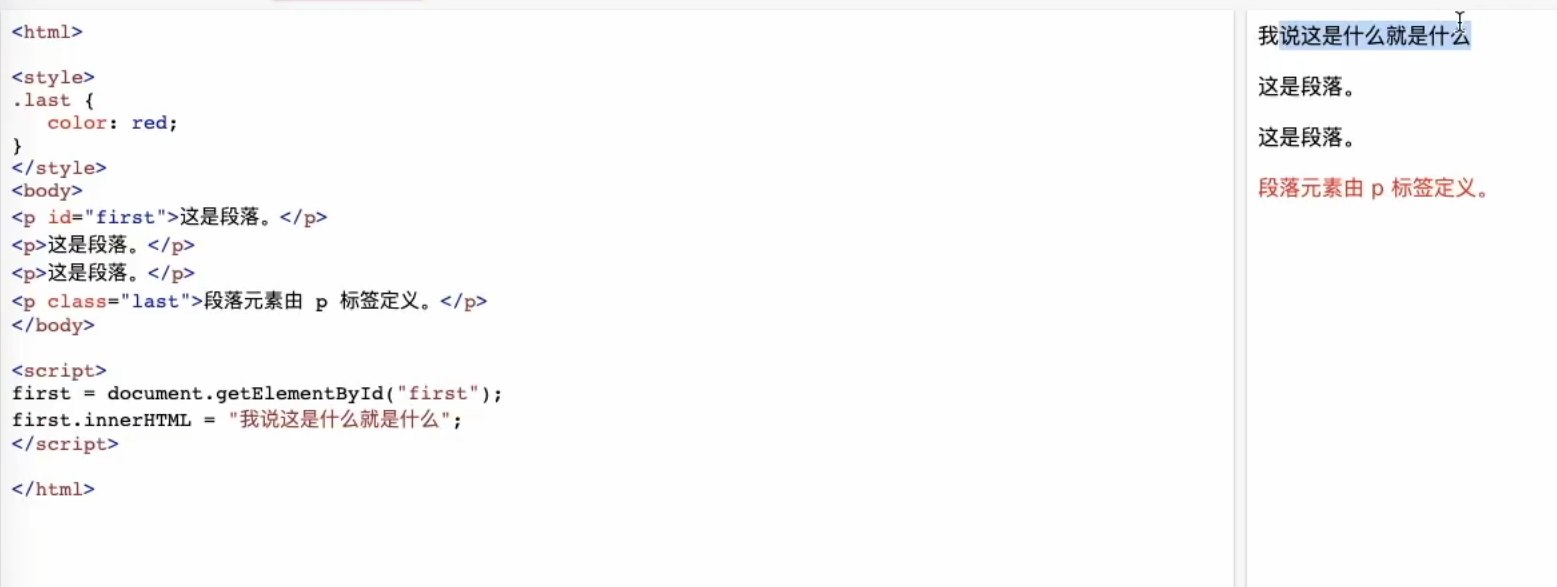
而这个dom就是经浏览器渲染之后的标签。虽然css和js是不能修改html文件中的标签,但能修改dom。
Related Articles
2025-02-18
mitmproxy App爬虫
安装什么内容?首先让pc和手机连接同一个局域网,在pc上安装好mitmproxy并安装好证书后,还要在安卓手机的设置中心也安装好证书,并设置代理(通过ipconfig命令查看主机的ip地址,) 这样我们就可以在使用mitmproxy这个代理了。 开始工作在terminal开启代理,指定为8888端口 1mitmproxy -p 8888 或者我们可以用mitmdump可以对接python脚本 1mitmdump -s script.py -p 8888 当手机连上代理后, 此时,手机上的request和response都被代理抓取了下来,
2025-02-16
scrapy
概况下面就是scrapy的大致框架图,我们先做一个案例再慢慢介绍 准备工作确保scrapy项目要在根目录上运行,原因是: Scrapy 项目通常是一个 Python 包,当你在 Scrapy 项目的根目录之外运行代码时,Python 可能无法正确找到 scrapytutorial 这个包,导致 无法解析 scrapytutorial.items。这是因为 Python 的 模块搜索路径 (sys.path) 不包含 Scrapy 项目的根目录。 创建scrapy项目 12scrapy startproject <project_name>scrapy startproject scrapytutorial 创建spider 12345cd <project_name>scrapy genspider <spider_name> <domain>cd scrapytutorialscrapy genspider quotes...
2025-02-18
记录一次cookies免登录
cookies的作用cookies在我们浏览器的客户端,通过cookies我们可以把我们的个人标识信息传送到服务器端,而在服务器端正好有与我们cookies相对应的session包含个人信息(登录信息,偏好信息,等等)。当我们访问服务器时(每一个requests都带有cookies),服务器会response我们的个人信息。这样我们每一次访问同一个域名网站就不用一直填写登录信息了。 爬虫中cookies的应用在爬虫中,我们每发送一次request都要把cookies带上(之前就是忽略了某些request的cookies导致找了很久都不知道哪里错) 在浏览器的开发者选项中,我们都能找到我们的cookies,我们只需要复制他们,并改写成字典形式,便可以传递到request中。 原始cookies 1wordpress_test_cookie=WP%20Cookie%20check;...
2025-07-08
正则表达式
Introduction在爬虫中,我们的目的就是要提取一大堆文本中的某些信息。我们就需要找到这些信息的共同特征,让计算机去匹配(match)。 正则表达式就是表达这些特征的重要手段。 一些特殊符号.: 表示除换行符之外的任意字符。 *: 表示前面的字符的0次到无限次,经过组合,就可以得到.*表示除换行符之外的任意多个字符。 ?: 表示前面的字符的0次或1次 +: 表示前面的表达式 出现 1 次或多次 \: 通过它可以让特殊符号成为普通符号,或者把普通符号变成特殊符号 \s*:跳过可能的空格 \d: (digital)表示一位数字 (): 提取里面的内容 (?:):非提取,某些爬虫可能会出现同一个数据,有多种不同的html文本格式,这是就需要搭配或者符号|。比如:(?:a|b)匹配a或者b .*:贪婪模式,获取最长的满足条件的字符串。 .*? :非贪婪模式,获取最短的能满足条件的字符串。 python中的正则表达式re是python中的正则表达式模块 findall以列表的形式返回所有满足正则表达式的字符串。 1re.findall(pattern, string,...
2025-07-02
python模拟ajax请求
Introduction经过大众好评的书籍的阅读,还有chatgpt的帮助,我成功完成了第一次ajax请求。 总的来说,ajax请求的来源就是: 由最原始的request URL直接暴露在源代码中,为了防止爬虫轻易地实现自动化自动抓取数据,从而把请求隐藏在JavaScript中(这种请求也叫Ajax请求),Ajax请求可以干很多东西,可能是直接response内容,也有可能是改变用户的状态,等等。从而避免了直接的URL获取。 查看JavaScript源代码,看看他在背后做了什么(发送ajax请求?获取源代码中的隐藏变量?改变用户状态?) 通过request模拟ajax请求, 通过触发事件,在浏览器开发者工具中,找到这个Ajax请求(通常是post,需要传递相关参数才能传递),并发送 (总之,就是通过python干JavaScript干的事情) 最终,我得到了想要的数据 JS分析1<p class="erphpdown-content-vip erphpdown-content-vip-see">您可免费查看此隐藏内容!<a...
Contents